
优化器是用来更新和计算影响模型训练和模型输出的网络参数,使其逼近或达到最优值,从而最小化(或最大化)损失函数。
随机梯度下降是最简单的优化器,它采用了简单的梯度下降法,只更新每一步的梯度,但是它的收敛速度会受到学习率的影响。
优点: 简单性,在优化算法中没有太多的参数需要调整,通过少量的计算量就可以获得比较好的结果。
缺点: 在某些极端情况下容易受到局部最小值的影响,也容易出现收敛的问题。
为解决 GD 中固定学习率带来的不同参数间收敛速度不一致的弊端,AdaGrad 和 RMSprop 诞生出来,为每个参数赋予独立的学习率。计算梯度后,梯度较大的参数获得的学习率较低,反之亦然。此外,为避免每次梯度更新时都独立计算梯度,导致梯度方向持续变化,Momentum 将上一轮梯度值加入到当前梯度的计算中,通过某种权重对两者加权求和,获得当前批次参数更新的梯度值。 Adam 结合了这两项考虑,既为每一个浮点参数自适应性地设置学习率,又将过去的梯度历史纳入考量,其实现原理如下:
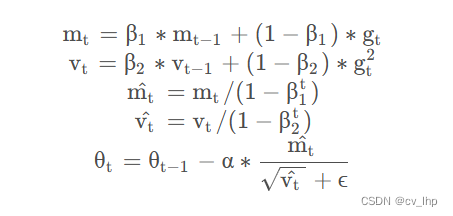
计算一阶、二阶动量矩,加入偏置修正,最后更新参数,gt表示t时刻梯度。从上述公式可以看出,训练前期的学习率和梯度更新是比较激进的,到后期逐渐平稳。虽然 Adam 优化器的使用会导致内存中多出两倍于原参数体量的占用,但与之换来的训练收益使得学术界并没有放弃这一高效的方法。
代码实现比较简单,照着公式敲就行了:
Adam 虽然收敛速度快,但没能解决参数过拟合的问题。学术界讨论了诸多方案,其中包括在损失函数中引入参数的 L2 正则项。这样的方法在其他的优化器中或许有效,但会因为 Adam 中自适应学习率的存在而对使用 Adam 优化器的模型失效,具体分析可见fastai的这篇文章:AdamW and Super-convergence is now the fastest way to train neural nets。AdamW 的出现便是为了解决这一问题,达到同样使参数接近于 0 的目的。具体的举措,是在最终的参数更新时引入参数自身:
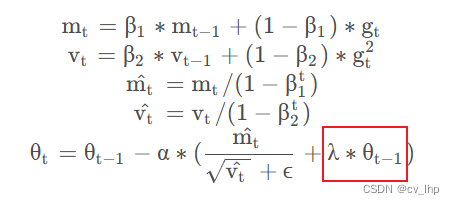
λ 即为权重衰减因子,常见的设置为 0.005/0.01。这一优化策略目前正广泛应用于各大预训练语言模型。
代码实现:
LAMB 优化器是 2019 年出现的一匹新秀,它将bert模型的预训练时间从3天压缩到了76分钟! LAMB 出现的目的是加速预训练进程,这个优化器也成为 NLP 社区为泛机器学习领域做出的一大贡献。在使用 Adam 和 AdamW 等优化器时,一大问题在于 batch size 存在一定的隐式上限,一旦突破这个上限,梯度更新极端的取值会导致自适应学习率调整后极为困难的收敛,从而无法享受增加的 batch size 带来的提速增益。LAMB 优化器的作用便在于使模型在进行大批量数据训练时,能够维持梯度更新的精度。具体来说,LAMB 优化器支持自适应元素级更新(adaptive element-wise updating)和准确的逐层修正(layer-wise correction)。LAMB 可将 BERT 预训练的批量大小扩展到 64K,且不会造成准确率损失。BERT 预训练包括两个阶段:1)前 9/10 的训练 epoch 使用 128 的序列长度,2)最后 1/10 的训练 epoch 使用 512 的序列长度。LAMB的算法如下:
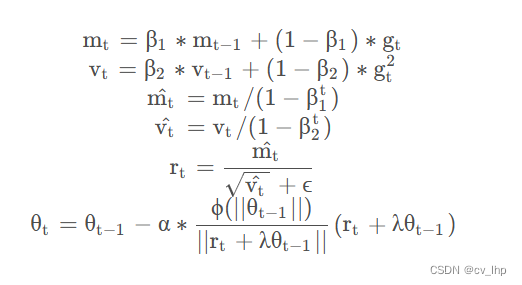
其中, ? 是一个可选择的映射函数,一种是 ? ( z ) = z ,另一种则为起到归一化作用的 m i n ( m a x ( z , γ l ) , γ u ) 。 γ l , γ u \phi 是 一 个 可 选 择 的 映 射 函 数 ,一种是\phi(z)=z, 另一种则为起到归一化作用的min(max(z,\gamma_l),\gamma_u)。 \gamma_l,\gamma_u ?是一个可选择的映射函数,一种是?(z)=z,另一种则为起到归一化作用的min(max(z,γl?),γu?)。γl?,γu?为预先设定的超参数,分别代表参数调整的下界和上界。这一简单的调整所带来的实际效果非常显著。使用 AdamW 时,batch size 超过 512 便会导致模型效果大幅下降,但在 LAMB 下,batch size 可以直接提到 32,000 而不会导致精度损失。
以下是 LAMB 优化器的 tensorflow1.x 代码,可作为参考以理解算法:
公司名称: 亚游-亚游娱乐-注册登录站
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

