深度学习的目标是通过不断改变网络参数,使得参数能够对输入做各种非线性变换拟合输出,本质上就是一个函数去寻找最优解,所以如何去更新参数是深度学习研究的重点。通常将更新参数的算法称为优化器,字面理解就是通过什么算法去优化网络模型的参数。常用的优化器就是梯度下降。接下来讲的就是梯度下降和进一步优化梯度下降的各种算法。
梯度下降算法特别容易理解,函数的梯度方向表示了函数值增长速度最快的方向,那么和它相反的方向就可以看作是函数值减少速度最快的方向。对机器学习模型优化的问题,当目标设定为求解目标函数最小值时,只要朝着梯度下降的方向前进,就能不断逼近最优值。
根据用多少样本量来更新参数将梯度下降分为三类:BGD,SGD,MBGD
(1)BGD:Batch gradient descent
每次使用整个数据集计算损失后来更新参数,很显然计算会很慢,占用内存大且不能实时更新,优点是能够收敛到全局最小点,对于异常数据不敏感。
(2)SGD:Stochastic gradient descent
这就是常说的随机梯度下降,每次更新度随机采用一个样本计算损失来更新参数,计算比较快,占用内存小,可以随时新增样本。这种方式对于样本中的异常数据敏感,损失函数容易震荡。容易收敛到局部极小值,但由于震荡严重,会跳出局部极小,从而寻找到接近全局最优的解。
(3)MBGD: Mini-batch gradient descent
小批量梯度下降,很好理解,将BGD和SGD结合在一起,每次从数据集合中选取一小批数据来计算损失并更新网络参数。
综上;
| 用多少样本量来更新参数 | 1 | 部分 | 全部 |
| 梯度下降类型 | 随机梯度下降(SGD) | 小批量梯度下降(MBGD) | 批量梯度下降(BGD) |
在有些地方是另一套说法;但划分标准是相同的,只是名字不同:
| 用多少样本量来更新参数 | 1 | 部分 | 全部 |
| 梯度下降类型 | 随机梯度下降(SGD) | 批量梯度下降(BGD) | 标准梯度下降(GD) |
动量优化方法是在梯度下降法的基础上进行的改变,具有加速梯度下降的作用。一般有标准动量优化方法Momentum、NAG(Nesterov accelerated gradient)动量优化方法。
?
自适应学习率优化算法针对于机器学习模型的学习率,传统的优化算法要么将学习率设置为常数要么根据训练次数调节学习率。极大忽视了学习率其他变化的可能性。然而,学习率对模型的性能有着显著的影响,因此需要采取一些策略来想办法更新学习率,从而提高训练速度。?
目前的自适应学习率优化算法主要有:AdaGrad算法,RMSProp算法,Adam算法以及AdaDelta算法。
思想:
算法描述:
思想:
算法描述:
思想:AdaGrad算法和RMSProp算法都需要指定全局学习率,AdaDelta算法结合两种算法每次参数的更新步长即:
?
算法描述:
评价:
思想:
算法描述:
评价:Adam通常被认为对超参数的选择相当鲁棒,尽管学习率有时需要从建议的默认修改。
终于结束的漫长的理论分析,下面对各种优化器做一些有趣的比较。
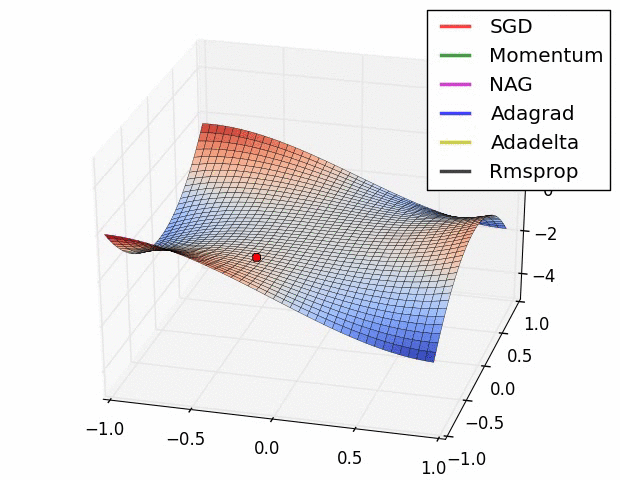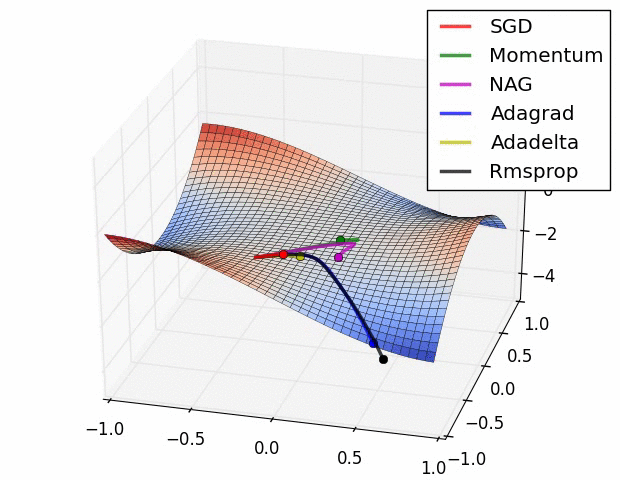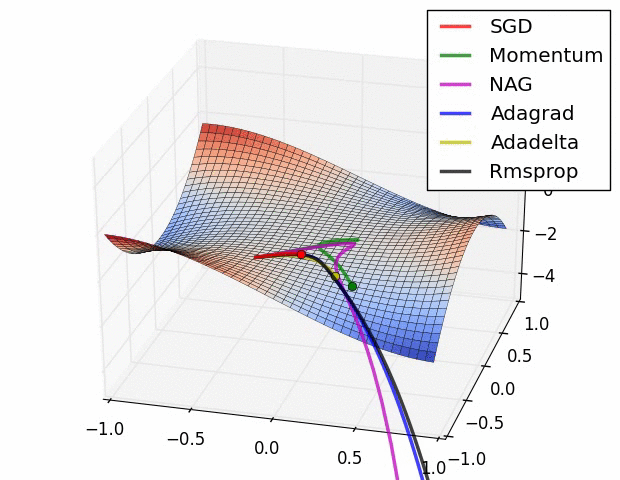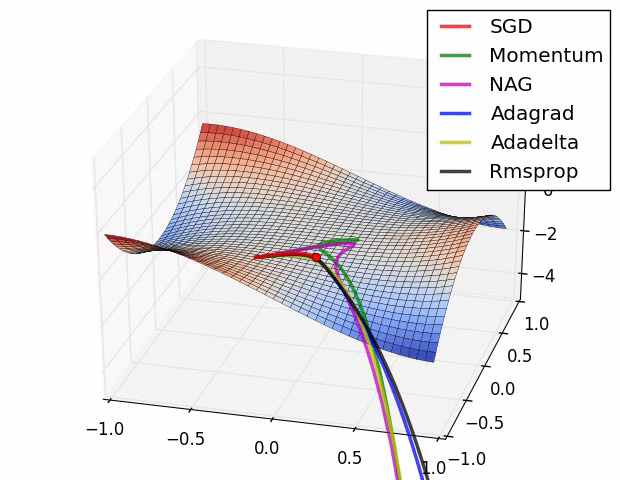
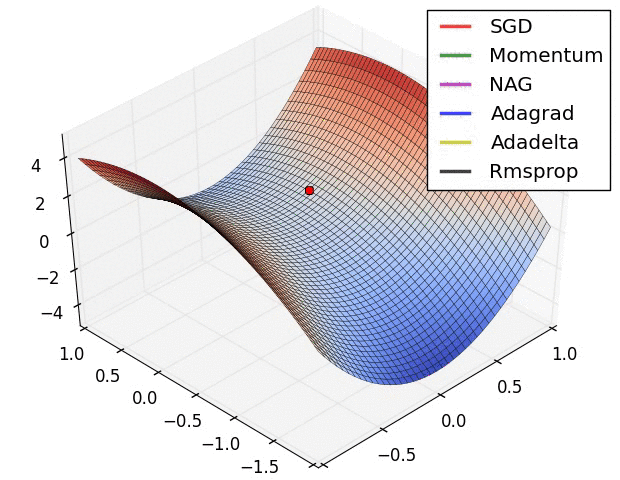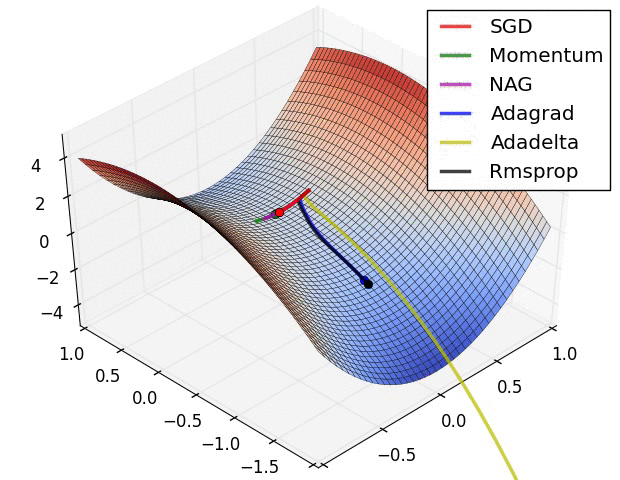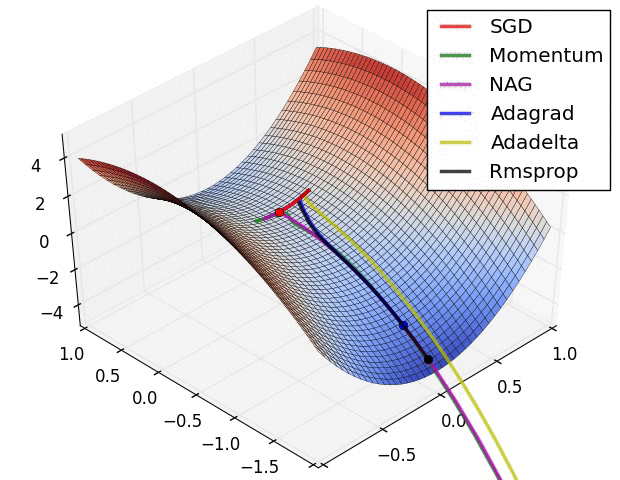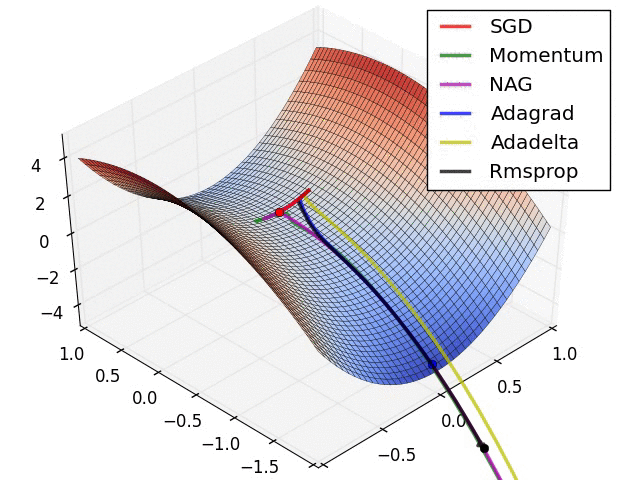
(1) 示例一
?
?
上图描述了在一个曲面上,6种优化器的表现,从中可以大致看出:
① 下降速度:
② 下降轨迹:
(2) 示例二
?
?
上图在一个存在鞍点的曲面,比较6中优化器的性能表现,从图中大致可以看出:
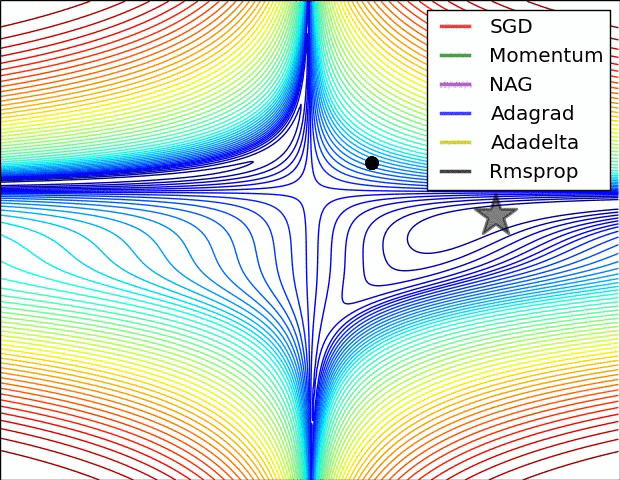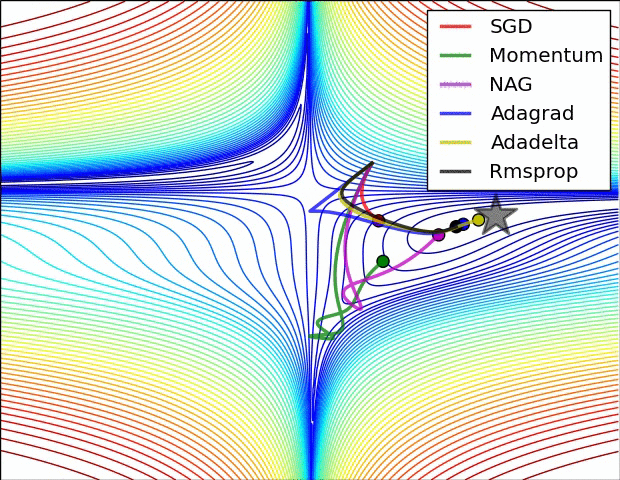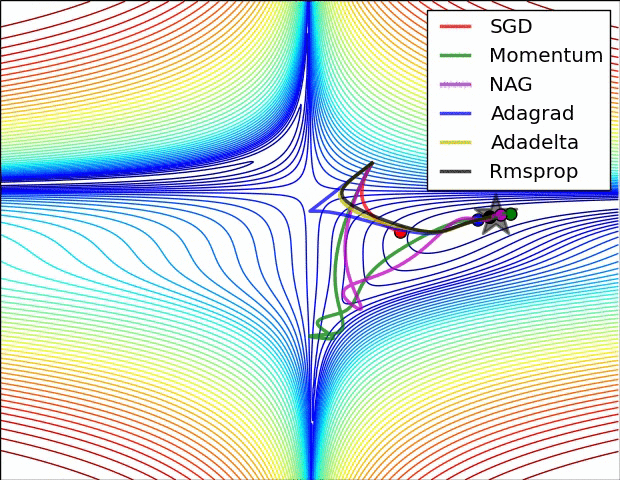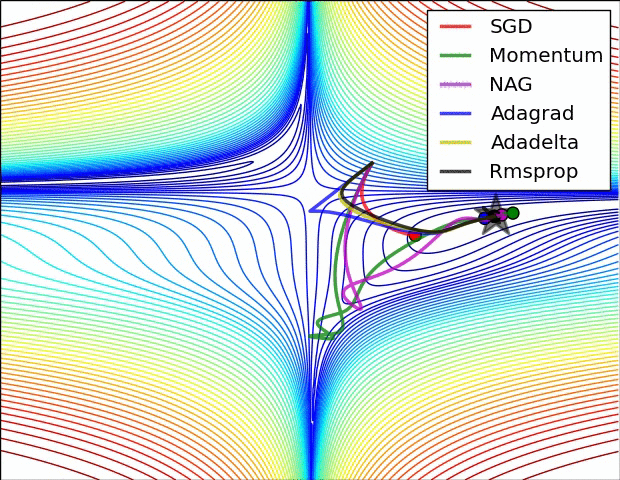
(3) 示例三
?
?
上图比较了6种优化器收敛到目标点(五角星)的运行过程,从图中可以大致看出:
① 在运行速度方面
② 在收敛轨迹方面
Tensorflow中封装了一系列的优化器:
下面采用选取几种优化器应用于UCI数据集iris.data简单的分类问题。为了简单起见,初始代码可以参考机器学习:过拟合、神经网络Dropout中没使用Dropout之前的代码。修改一行调用优化器的代码:
(1) 使用SGD优化器
(2) 使用AdaGrad优化器
?
(3) 使用Momentum优化器
?
(4) 使用NAG优化器
?
?
(5) 使用RMSProp优化器
?
(6) 使用Adam优化器
?
点评:Adam优化器的表现可圈可点,比RMSProp优化器要稳定。?
(2) 使用AdaDelta优化器
优化器的代码为:
?
总评:
参考资料
为什么说随机最速下降法(SGD)是一个很好的方法??
深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)?
Lan Goodfellow: Deep learning. 深度学习【中文版】?
常见优化算法 (caffe和tensorflow对应参数)
公司名称: 亚游-亚游娱乐-注册登录站
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号