
目录
一、优化器
(优化器有什么用?)
深度学习模型通过引入损失函数,用来计算目标预测的错误程度。根据损失函数计算得到的误差结果,需要对模型参数(即权重和偏差)进行很小的更改,以期减少预测错误。但问题是如何知道何时应更改参数,如果要更改参数,应更改多少? 这就是引入优化器的时候了。简单来说, 优化器可以优化损失函数,优化器的工作是以使损失函数最小化的方式更改可训练参数,损失函数指导优化器朝正确的方向移动。
优化器即优化算法是用来求取模型的最优解的,通过比较神经网络自己预测的输出与真实标签的差距,也就是Loss函数。为了找到最小的loss(也就是在神经网络训练的反向传播中,求得局部的最优解),通常采用的是梯度下降(Gradient Descent)的方法,而梯度下降,便是优化算法中的一种。 总的来说可以分为三类,一类是梯度下降法( Gradient Descent ),一类是动量优化法( Momentum ),另外就是自适应学习率优化算法。
常见的一些优化器有:SGD 、Adagrad 、Adadelta 、RMSprop 、Adam 、Adamax 、Nadam 、TFOptimizer 等等。
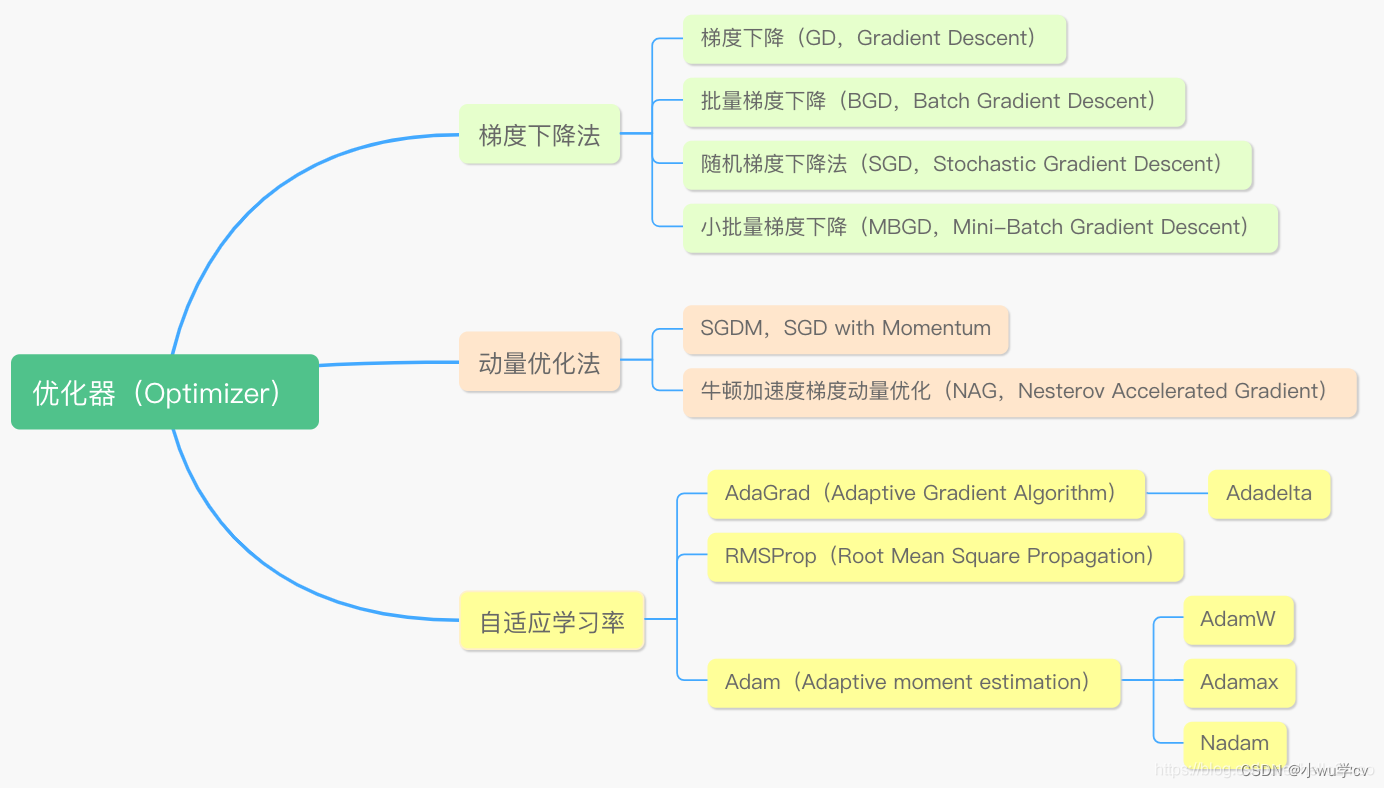
二、各优化器
假设要学习训练的模型参数为W ,代价函数为J(W),则代价函数关于模型参数的偏导数即相关梯度为ΔJ(W),学习率为ηt,则使用梯度下降法更新参数为:
其中, _η_为学习率、
从表达式来看,模型参数的更新调整,与代价函数关于模型参数的梯度有关,即沿着梯度的方向不断减小模型参数,从而最小化代价函数。
基本策略可以理解为” 在有限视距内寻找最快路径下山“,因此每走一步,参考当前位置最陡的方向(即 梯度)进而迈出下一步。可以形象的表示为:
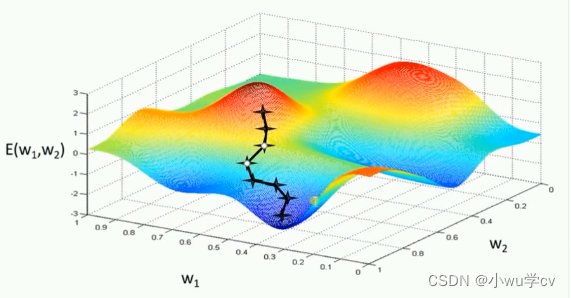
评价:标准梯度下降法主要有两个缺点:
训练速度慢:每走一步都要要计算调整下一步的方向,下山的速度变慢。在应用于大型数据集中,每输入一个样本都要更新一次参数,且每次迭代都要遍历所有的样本。会使得训练过程及其缓慢,需要花费很长时间才能得到收敛解。这样就产生了很多比较新奇的优化器(SGD ,BGD ,Mini-batch GD 等)。批量梯度下降法(BGD )、随机梯度下降法(SGD )、小批量梯度下降法。
容易陷入局部最优解:由于是在有限视距内寻找下山的反向。当陷入平坦的洼地,会误以为到达了山地的最低点,从而不会继续往下走。所谓的局部最优解就是鞍点。落入鞍点,梯度为0 ,使得模型参数不在继续更新。(对于非凸函数而言,容易陷入局部最优解)
均匀地、随机选取其中一个样本,
SGD 的更新公式为:
基本策略可以理解为随机梯度下降像是一个 盲人下山,不用每走一步计算一次梯度,但是他总能下到山底,只不过过程会显得扭扭曲曲。
优点:
虽然SGD 需要走很多步的样子,但是对梯度的要求很低(计算梯度快)。而对于引入噪声,大量的理论和实践工作证明,只要噪声不是特别大,SGD 都能很好地收敛。
应用大型数据集时,训练速度很快。比如每次从百万数据样本中,取几百个数据点,算一个SGD 梯度,更新一下模型参数。相比于标准梯度下降法的遍历全部样本,每输入一个样本更新一次参数,要快得多。
缺点:
SGD在随机选择梯度的同时会引入噪声, 使得权值更新的方向不一定正确。此外,SGD 也 没能单独克服局部最优解的问题。
官方框架的代码:
(pytorch)
momentum(float)- 动量,通常设置为0.9,0.8
dampening(float)- dampening for momentum ,暂时不了其功能,在源码中是这样用的:buf.mul (momentum).add(1 – dampening, d_p),值得注意的是,若采用nesterov,dampening必须为 0.
weight_decay(float)- 权值衰减系数,也就是L2正则项的系数
(tensorflow2)
随机梯度下降法,支持动量参数,支持学习衰减率,支持Nesterov动量
每次迭代使用m 个样本来对参数进行更新,MBGD 的更新公式为:
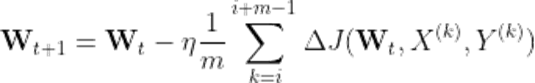
其中表示t 时刻的模型参数。
从表达式来看,模型参数的调整更新与小部分的输入样本的代价函数的和(即批量/全局误差)有关。即每次权值调整发生在批量样本输入之后,而不是每输入一个样本就更新一次模型参数。这样就会大大加快训练速度。
基本策略可以理解为, 在下山之前掌握了附近的地势情况,选择相对的总体平均梯度最小的方向下山。
评价:
1、优点:使用mini-batch 的时候, 可以收敛得很快,有一定摆脱局部最优的能力。
2、缺点:
BGD、SGD 、MBGD 分别为批量梯度下降算法、随机梯度下降算法、小批量梯度下降算法。BGD 在训练的时候选用所有的训练集进行计算,SGD 在训练的时候只选择一个数据进行训练,而MBGD 在训练的时候只选择小部分数据进行训练。这三个优化算法在训练的时候虽然所采用的的数据量不同,但是他们在进行参数优化的时候是相同的。
这种梯度更新算法简洁,当学习率取值恰当时,可以收敛到全面最优点(凸函数)或局部最优点(非凸函数)。 但其还有很大的不足点:
1 、 对超参数学习率比较敏感(过小导致收敛速度过慢,过大又越过极值点)。
2 、学习率除了敏感,有时还会因其在 迭代过程中保持不变,很容易造成算法被卡在鞍点的位置。
3 、在较平坦的区域,由于 梯度接近于 0 ,优化算法会因误判,在还未到达极值点时,就提前结束迭代,陷入局部极小值。
其他的SGD优化器–官方框架的代码: :
ASGD(随机平均梯度下降)
(pytorch)
牛顿加速梯度动量优化方法(NAG, Nesterov accelerated gradient):拿着上一步的速度先走一小步,再看当前的梯度然后再走一步。
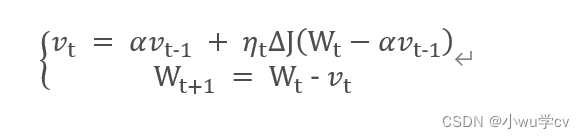
SGDM 对比NAG 如下:
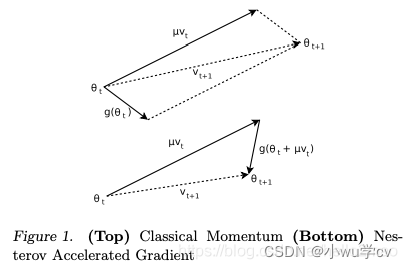
其中,
理解策略:在Momentun 中小球会盲目地跟从下坡的梯度,容易发生错误。所以需要一个更聪明的小球,能提前知道它要去哪里,还要知道走到坡底的时候速度慢下来而不是又冲上另一个坡。计算
在凸批量梯度的情况下,Nesterov 动量将额外误差收敛率从O(1/k)(k 步后)改进到O(1/k2)。然而,在随机梯度情况下,Nesterov 动量对收敛率的作用却不是很大。
优点: 梯度下降的方向更加准确
缺点: 对收敛率作用不是很大
使用动量(Momentum)的随机梯度下降法(SGD),主要思想是引入一个积攒历史梯度信息动量来加速SGD 。
理解策略为:由于当前权值的改变会受到上一次权值改变的影响,类似于小球向下滚动的时候带上了惯性。这样可以加快小球向下滚动的速度。
从训练集中取一个大小为n 的小批量
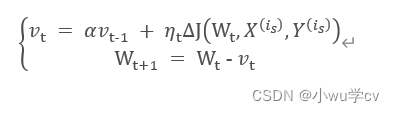
其中,
动量主要解决SGD 的两个问题: 一是随机梯度的方法(引入的噪声);二是 Hessian 矩阵病态问题(可以理解为 SGD 在收敛过程中和正确梯度相比来回摆动比较大的问题)。
SGDM相比 SGD 优势明显,加入动量后,参数更新就可以保持之前更新趋势,而不会卡在当前梯度较小的点了。
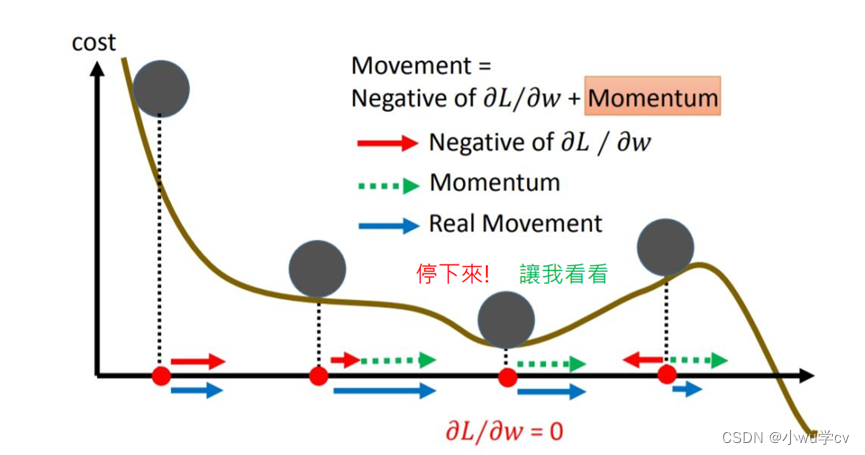
美中不足的是, SGDM 没有考虑对学习率进行自适应更新,故学习率的选择很关键。
在梯度方向改变时,momentum能够降低参数更新速度,从而减少震荡;在梯度方向相同时,momentum可以加速参数更新, 从而加速收敛。动量移动得更快(因为它积累的所有动量)。动量有机会逃脱局部极小值(因为动量可能推动它脱离局部极小值)
论文网址:https://arxiv.org/pdf/1609.04747.pdf
博客:深度学习中的优化算法之AdaGrad_fengbingchun的博客-CSDN博客_adagrad
AdaGrad算法,独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平均值总和的平方根。具有代价函数最大梯度的参数相应地有个快速下降的学习率,而具有小梯度的参数在学习率上有相对较小的下降。与SGD 的区别在于,学习率除以 前t-1 迭代的梯度的平方和。 故称为自适 应 梯度下降 。
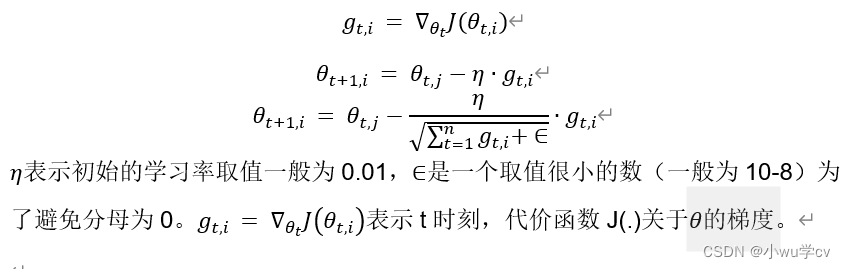
从表达式可以看出,对出现比较多的类别数据,Adagrad 给予越来越小的学习率,而对于比较少的类别数据,会给予较大的学习率。因此Adagrad 适用于数据稀疏或者分布不平衡的数据集。
Adagrad 的主要优势在于不需要人为的调节学习率,它可以自动调节;缺点在于,随着迭代次数增多,学习率会越来越小,最终会趋近于0,使得训练提前结束,无法继续学习。
Adagrad有个致命问题,就是没有考虑迭代衰减。极端情况,如果刚开始的梯度特别大,而后面的比较小,则学习率基本不会变化了,也就谈不上自适应学习率了。这个问题在RMSProp中得到了修正
官方框架的代码:
(pytorch)
论文地址:https://arxiv.org/pdf/1609.04747.pdf
博客:深度学习中的优化算法之Adadelta_fengbingchun的博客-CSDN博客_adadelta
Adadelta依然对学习率进行了约束,但是在计算上进行了简化。


其中,E 代表求期望,RMS(Root Mean Squared ,均方根)
特点:
官方框架的代码:
(pytorch)
(tensorflow2)
论文网址:https://arxiv.org/pdf/1609.04747.pdf
博客地址:深度学习中的优化算法之RMSProp_fengbingchun的博客-CSDN博客_rmsprop
RMSprop可以看做Adadelta 的一个特例。RMSProp 算法修改了AdaGrad 的梯度积累为指数加权的移动平均,使得其在非凸设定下效果更好。

特点
官方框架的代码:
(pytorch)
(tensorflow2)
除学习率可调整外,建议保持优化器的其他默认参数不变。该优化器通常是面对递归神经网络时的一个良好选择
论文网址: https://arxiv.org/pdf/1609.04747.pdf
博客网址: 深度学习中的优化算法之Adam_fengbingchun的博客-CSDN博客_adam优化算法
Adam 是SGDM 和RMSProp 的结合,它基本解决了之前提到的梯度下降的一系列问题,比如随机小样本、自适应学习率、容易卡在梯度较小点等问题,2015 年提出。如下:

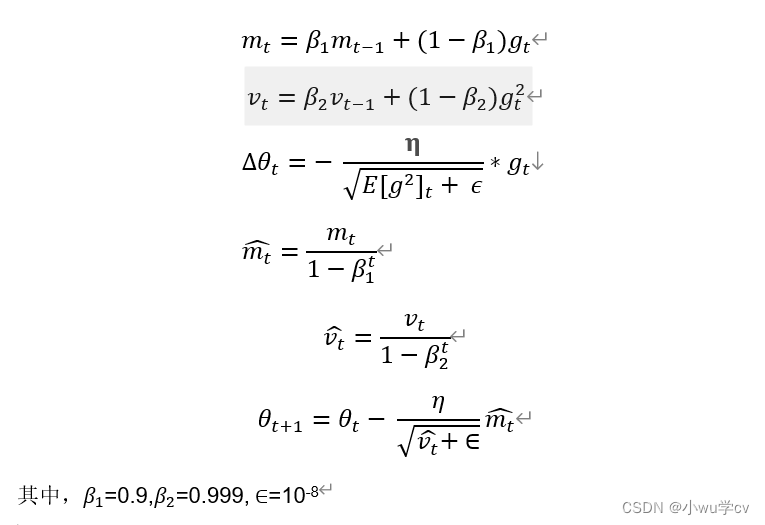
评价:
主要包含以下几个显著的优点:
官方框架的代码:
(pytorch)
(tensorflow2)
论文网址:https://arxiv.org/pdf/1412.6980.pdf、 https://arxiv.org/pdf/1609.04747.pdf
参考博客: Pytorch优化器全总结(二)Adadelta、RMSprop、Adam、Adamax、AdamW、NAdam、SparseAdam_小殊小殊的博客-CSDN博客_pytorch nadam

Adamax 总结
Adamax 是Adam的一种变体,此方法对学习率的上限提供了一个更简单的范围。总的来说跟Adam效果差不了多少。
推荐程度:非常推荐
官方框架的代码:
(pytorch)
(tensorflow2)
参考论文:https://arxiv.org/pdf/1412.6980.pdf
参考博客: Pytorch优化器全总结(二)Adadelta、RMSprop、Adam、Adamax、AdamW、NAdam、SparseAdam_小殊小殊的博客-CSDN博客_pytorch nadam


AdamW 总结
因为Adam的学习率自适应的,而L2正则遇到自适应学习率后效果不理想,所以使用adam+权重衰减的方式解决问题。多说一句,如果epoch比较多推荐使用 SGD(无momentum)+ L2正则化;poch比较少推荐使用AdamW。比Adam收敛得更快,参数更稀疏。
官方框架的代码:
(pytorch)
(tensorflow2)
无
参考论文:https://arxiv.org/pdf/1412.6980.pdf
参考博客:链接 Pytorch优化器全总结(二)Adadelta、RMSprop、Adam、Adamax、AdamW、NAdam、SparseAdam_小殊小殊的博客-CSDN博客_pytorch nadam 链接


NAdam 总结
优点:具有Adam的优点的同时,在也兼具NAG收敛速度快、波动也小的特点。(NAdam 是在 Adam 中引入 Nesterov 加速效果。)
推荐程度:推荐,在想使用带动量的RMSprop,或者Adam的地方,大多可以使用NAdam取得更好的效果。
官方框架的代码:
(pytorch)
(tensorflow2)
三、 优化器之间的对比
机器学习:各种优化器Optimizer的总结与比较_SanFanCSgo的博客-CSDN博客_optimizer
(1) 示例一
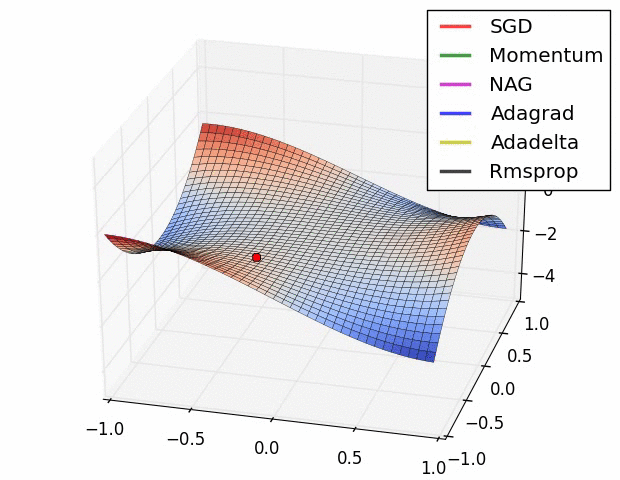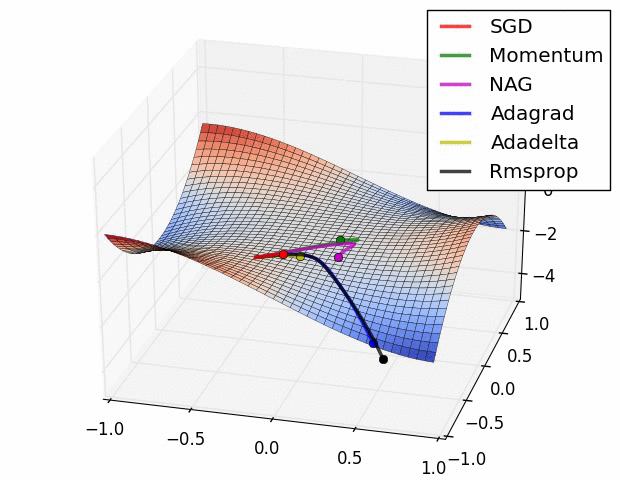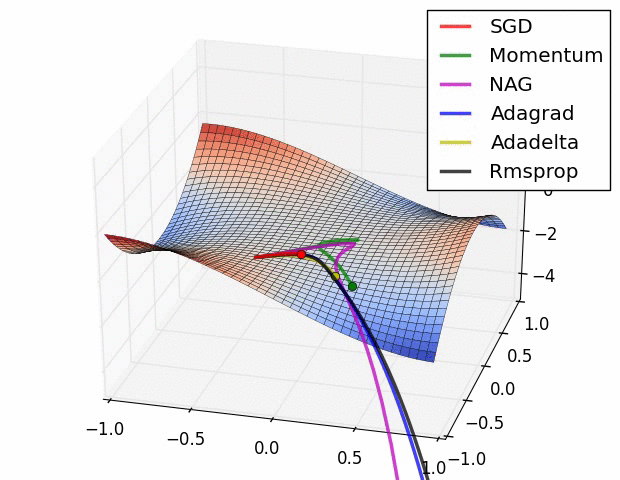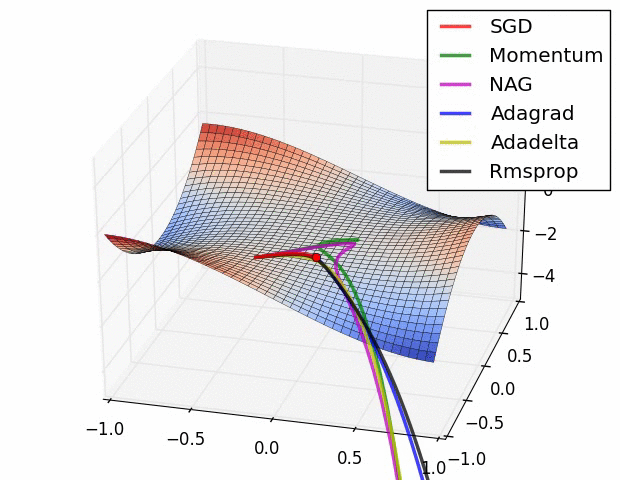
上图描述了在一个曲面上, 6 种优化器的表现,从中可以大致看出:
三个自适应学习优化器Adagrad、RMSProp与AdaDelta的下降速度明显比SGD要快,其中,Adagrad和RMSProp齐头并进,要比AdaDelta要快。
两个动量优化器Momentum和NAG由于刚开始走了岔路,初期下降的慢;随着慢慢调整,下降速度越来越快,其中NAG到后期甚至超过了领先的Adagrad和RMSProp。
SGD和三个自适应优化器轨迹大致相同。两个动量优化器初期走了”岔路”,后期也调整了过来。
示例二
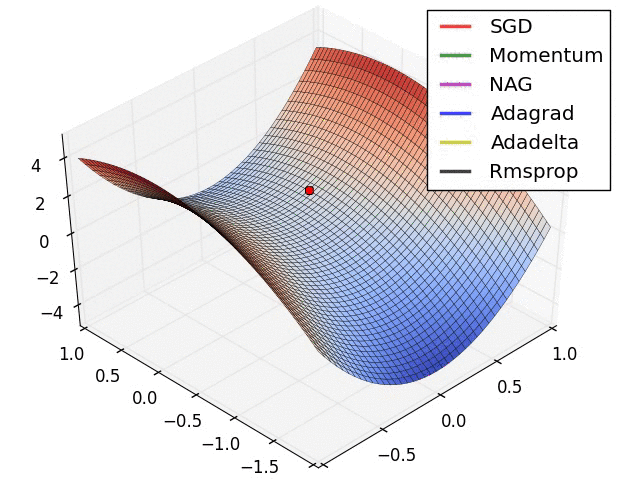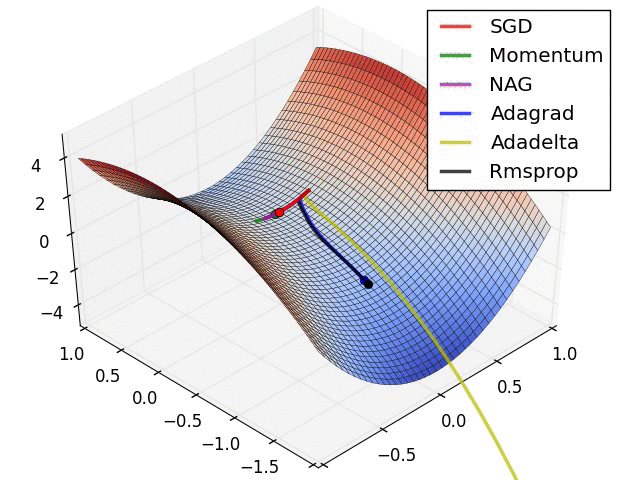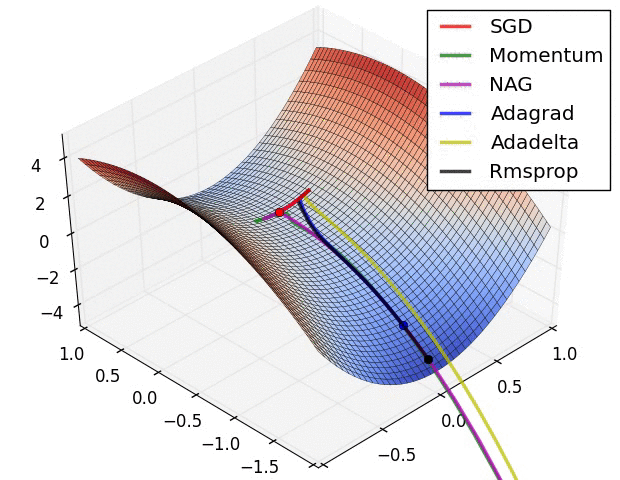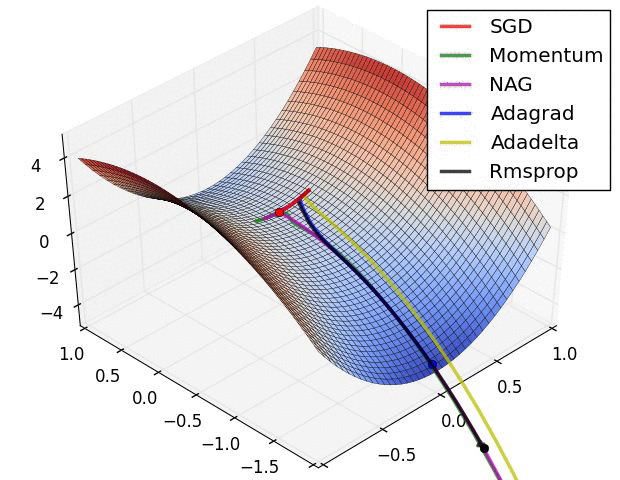
上图在一个存在鞍点的曲面,比较6 中优化器的性能表现,从图中大致可以看出:
三个自适应学习率优化器没有进入鞍点,其中,AdaDelta 下降速度最快,Adagrad 和RMSprop 则齐头并进。
两个动量优化器Momentum 和NAG 以及SGD 都顺势进入了鞍点。但两个动量优化器在鞍点抖动了一会,就逃离了鞍点并迅速地下降,后来居上超过了Adagrad 和RMSProp 。
很遗憾,SGD 进入了鞍点,却始终停留在了鞍点,没有再继续下降。
示例三

上图比较了6 种优化器收敛到目标点(五角星)的运行过程,从图中可以大致看出:
两个动量优化器Momentum 和NAG 的速度最快,其次是三个自适应学习率优化器AdaGrad 、AdaDelta 以及RMSProp ,最慢的则是SGD 。
两个动量优化器虽然运行速度很快,但是初中期走了很长的”岔路”。
三个自适应优化器中,Adagrad 初期走了岔路,但后来迅速地调整了过来,但相比其他两个走的路最长;AdaDelta 和RMSprop 的运行轨迹差不多,但在快接近目标的时候,RMSProp 会发生很明显的抖动。
SGD相比于其他优化器,走的路径是最短的,路子也比较正。
常见的优化器(Optimizer)原理_hello2mao的博客-CSDN博客_优化器原理
Validation accuracy (验证集acc )
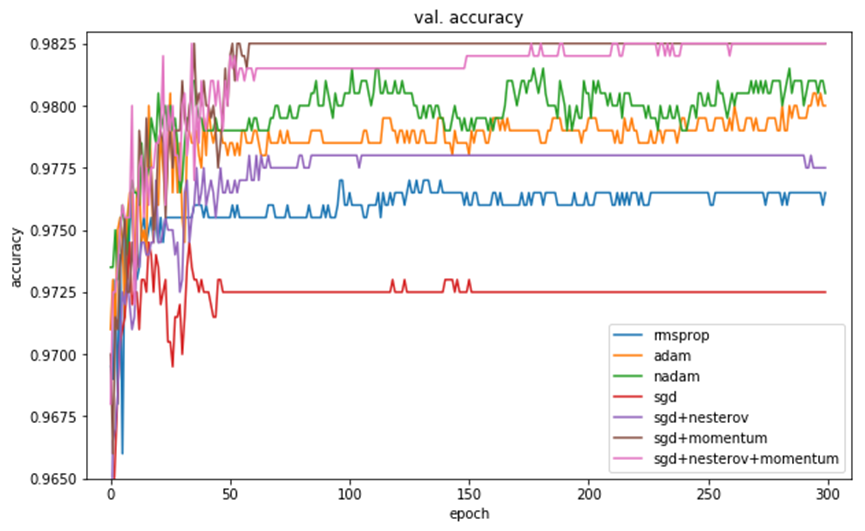
Training accuracy (训练集acc )
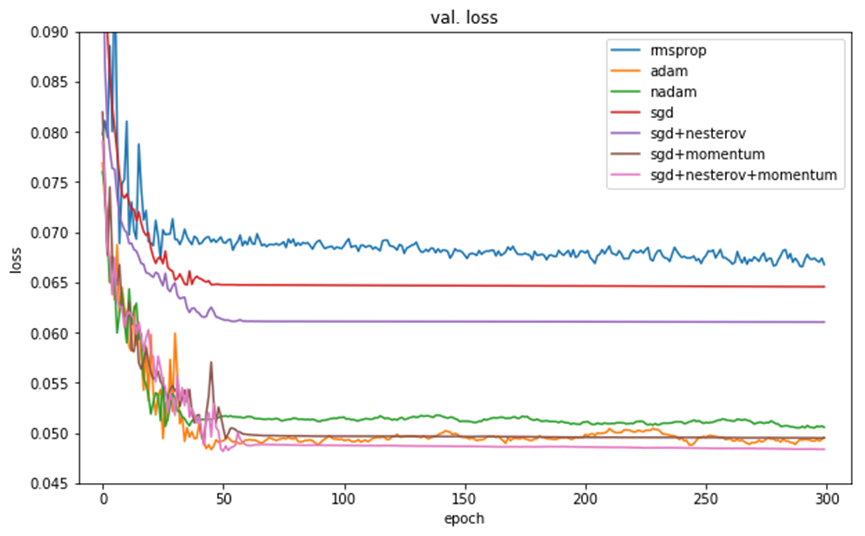
Validation loss (测试集loss )
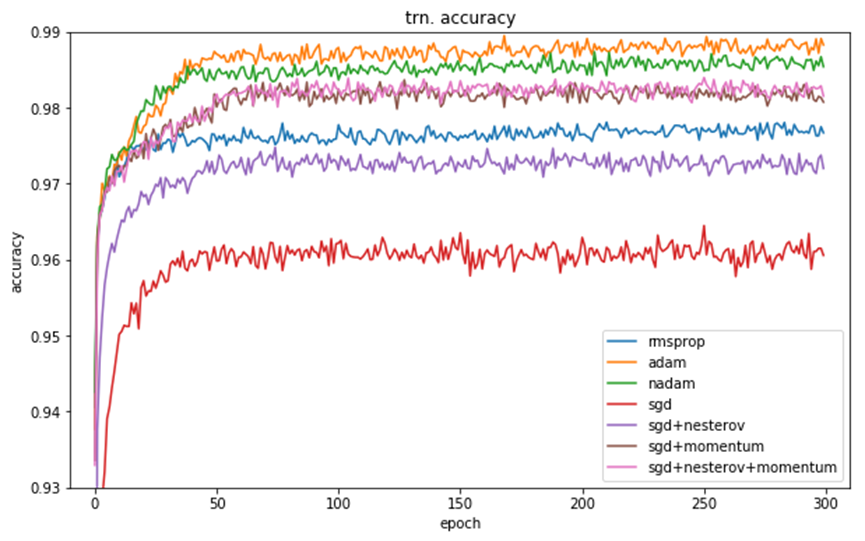
Training loss (训练集loss )
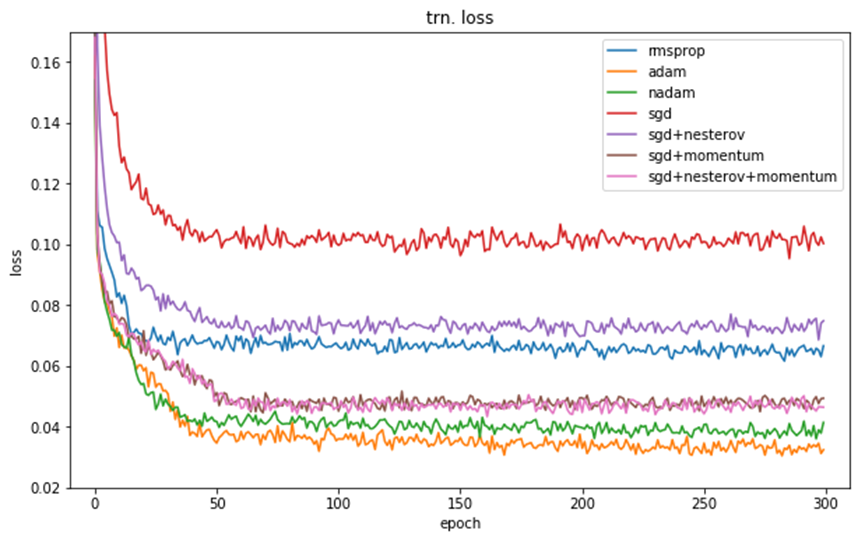
四、优化器的选择
(这里我引入一些大佬博客的想法,没有改动)
【深度学习】优化器详解_LogosTR_的博客-CSDN博客_优化器是什么
1. 优化算法的选择
(1)对于稀疏数据,尽量使用学习率可自适应的算法,不用手动调节,而且最好采用默认参数
(2)SGD通常训练时间最长,但是在好的初始化和学习率调度方案下,
(3)结果往往更可靠。但SGD容易困在鞍点,这个缺点也不能忽略。
(4)如果在意收敛的速度,并且需要训练比较深比较复杂的网络时,推荐使用学习率自适应的优化方法。
(5)Adagrad,Adadelta和RMSprop是比较相近的算法,表现都差不多。
(6)在能使用带动量的RMSprop或者Adam的地方,使用Nadam往往能取得更好的效果。
2. 优化 SGD 的其他策略
2.1. Shuffling and Curriculum Learning
Shuffling就是打乱数据,每一次epoch之后 shuffle一次数据,可以避免训练样本的先后次序影响优化的结果。但另一方面,在有些问题上,给训练数据一个有意义的顺序,可能会得到更好的性能和更好的收敛。这种给训练数据建立有意义的顺序的方法被叫做Curriculum Learning。
2.2. Batch Normalization
(1) 为了有效的学习参数,我们一般在一开始把参数初始化成0均值和单位方差。但是在训练过程中,参数会被更新到不同的数值范围,使得normalization的效果消失,从而导致训练速度变慢或梯度爆炸等等问题(当网络越来越深的时候)。
BN给每个batch的数据恢复了normalization,同时这些对数据的更改都是可还原的,即normalization了中间层的参数,又没有丢失中间层的表达能力。
(2) 使用BN之后,我们就可以使用更高的学习率,也不用再在参数初始化上花费那么多注意力。
(3) BN还有正则化的作用,同时也削弱了对Dropout的需求。
2.3. Early Stopping
在训练的时候我们会监控validation的误差,并且会(要有耐心)提前停止训练,如果验证集的error没有很大的改进。
2.4. Gradient noise
在梯度更新的时候加一个高斯噪声:
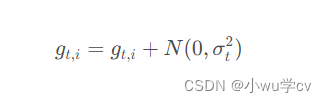
方差值的初始化策略是:
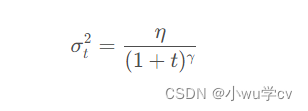
Neelakantan等人表明,噪声使得网络的鲁棒性更好,而且对于深度复杂的网络训练很有帮助。他们猜想添加了噪声之后,会使得模型有更多机会逃离局部最优解(深度模型经常容易陷入局部最优解)
优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam)_糖葫芦君的博客-CSDN博客_adam改进
用Adam还是SGD?Adam的两大罪状—-这个更详细可以查看上面的链接。
3. 优化算法的常用 tricks
(1) 首先,各大算法孰优孰劣并无定论。如果是刚入门,优先考虑SGD+Nestero V Momentum或者Adam.(Standford 231n : The two recommended updates to use are either SGD+NesteroV Momentum or Adam)
(2)选择你熟悉的算法——这样你可以更加熟练地利用你的经验进行调参。充分了解你的数据——如果模型是非常稀疏的,那么优先考虑自适应学习率的算法。如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用自适应学习率的优化方法。
(3)根据你的需求来选择——在模型设计实验过程中,要快速验证新模型的效果,可以先用Adam进行快速实验优化;在模型上线或者结果发布前,可以用精调的SGD进行模型的极致优化。
(4)先用小数据集进行实验——有论文研究指出,随机梯度下降算法的收敛速度和数据集的大小的关系不大。因此可以先用一个具有代表性的小数据集进行实验,测试一下最好的优化算法,并通过参数搜索来寻找最优的训练参数。
(5)考虑不同算法的组合:先用Adam进行快速下降,而后再换到SGD进行充分的调优。切换策略可以参考本文介绍的方法。
(6)数据集一定要充分的打散( shuffle ):这样在使用自适应学习率算法的时候,可以避免某些特征集中出现,而导致的有时学习过度、有时学习不足,使得下降方向出现偏差的问题。
(7)训练过程中 持续监控训练数据和验证数据上的目标函数值以及精度或者AUC等指标的变化情况。对训练数据的监控是要保证模型进行了充分的训练——下降方向正确,且学习率足够高;对验证数据的监控是为了避免出现过拟合。
(8)制定一个合适的学习率衰减策略。可以使用定期衰减策略,比如每过多少个epoch就衰减一次;或者利用精度或者AUC等性能指标来监控,当测试集上的指标不变或者下跌时,就降低学习率。
学习率衰减
在训练模型的时候,通常会遇到这种情况:我们平衡模型的训练速度和损失后选择了相对合适的学习率,但是训练集的损失下降到一定的程度后就不再下降了,最后最小值在附近摆动,不会精确地收敛,这是因为mini-batch中有噪声。遇到这种情况通常可以通过适当降低学习率来实现。但是,降低学习率又会延长训练所需的时间。学习率衰减就是一种可以平衡这两者之间矛盾的解决方案。
几种梯度衰减的方式:

五、总结
本文章总结了常用的优化器,其中包括 梯度下降法、动量优化法和自适应学习率优化算法三种,分别从原理、公式、优缺点以及pytorch及tensorflow2的官方代码展示这几个方面进行演示,最后可视化对比了各个优化器之间的效果以及如何选择优化器。如果你觉得本章论文对你有帮助,请点个,谢谢。
六、主要的参考网址
常见的优化器(Optimizer)原理_hello2mao的博客-CSDN博客_优化器原理
Pytorch优化器全总结(一)SGD、ASGD、Rprop、Adagrad_小殊小殊的博客-CSDN博客_pytorch sgd
Pytorch优化器全总结(二)Adadelta、RMSprop、Adam、Adamax、AdamW、NAdam、SparseAdam(重置版)_小殊小殊的博客-CSDN博客_adadelta优化器
SGD — PyTorch 1.12 documentation
tf.keras.optimizers 常用的优化器_甜辣uu的博客-CSDN博客_tf.keras.optimizers.
tf.keras.optimizers.Nadam | TensorFlow v2.10.0
Original: https://blog.csdn.net/caip12999203000/article/details/127455203
Author: 小wu学cv
Title: 常用的优化器合集
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/716111/
转载文章受原作者版权保护。转载请注明原作者出处!
公司名称: 亚游-亚游娱乐-注册登录站
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

