
1 摘要
存储系统的参数调整是存储系统优化的一个重要方法,当前的参数调整实践通常涉及大量的基准调整周期,耗时耗力,所以需要一个无监督模型来进行参数调优,深度学习+增强学习可以实现这样一个无监督的存储系统优化模型,小到客户端-服务端系统,大到到数据中心,都可以使用这个模型。
2 问题
参数调优主要有四个问题:
(1) 由于电脑是一个非线性系统,各种变量相互关联,这使得改变某个参数后很难预测产生的效果。
(2) action和reward之间有延迟,因此很难判定系统输入(action)和系统输出(reward)之间的关系。
(3) 可调节的参数空间,范围巨大。
(4) 需要24x7的工作量。
深度学习+增强学习可以解决上述问题,尤其是能够解决action和reward之间的延迟问题,具体来说主要的解决方法是Q-Learning与经验重放相结合。
CAPES的主要优点在于:
(1) 不需要预先了解目标系统。
(2) 它只需要对目标系统进行很少的更改,设置各项参数时所需的停机时间也很少。
(3) 它可以连续运行以适应工作负载的动态变化。
(4) 它可以动态地为静态设置的参数选择最优值。
3 技术背景
Hyperparameter: 超参,属于机器学习算法里面的参数,用来区别目标系统里面的参数。超参主要用来调节改变机器学习算法,也就是在机器学习训练中,通过调超参,来改变算法本身,超参数优化的常用方法有贝叶斯优化、随机搜索和基于梯度的优化。这里与目标系统里的参数相区别,目标系统的参数是作为状态(state)来使用的。
Q-Learning: 即agent如何在环境中采取action来最大化reward, 最终通过reward来学习到Q值经验。agent对系统进行action输入,获得reward和observation(state)。
Q-learning举例子解释具体过程如下:
Q-learning:
(1) Q-learning思路
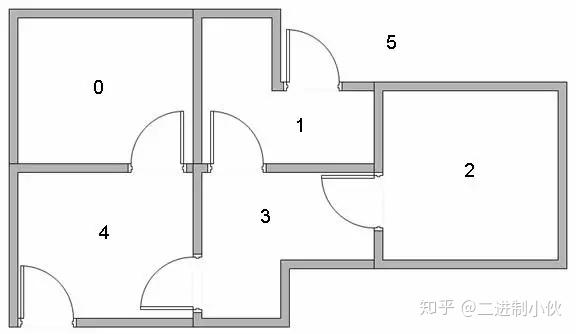
要解决的问题是:如上图 1.1 中有 5 个房间,分别被标记成0-4,房间外可以看成是一个大的房间,被标记成 5,现在智能程序 Agent 被随机丢在 0-4 号 5个房间中的任意 1 个,目标是让它寻找到离开房间的路(即:到达 5 号房间)。图片描述如下:
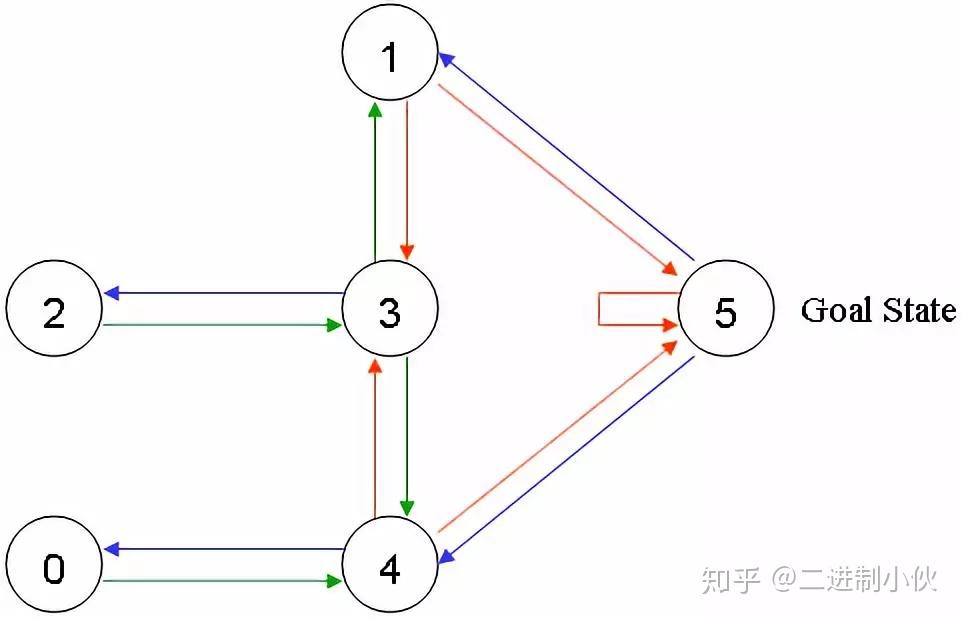
给可以直接移动到 5 号房间的动作奖励 100 分,即:图1.2中,4 到 5 、 1 到 5 和 5 到 5 的红线。在其它几个可移动的房间中移动的动作奖励 0 分。如下图:
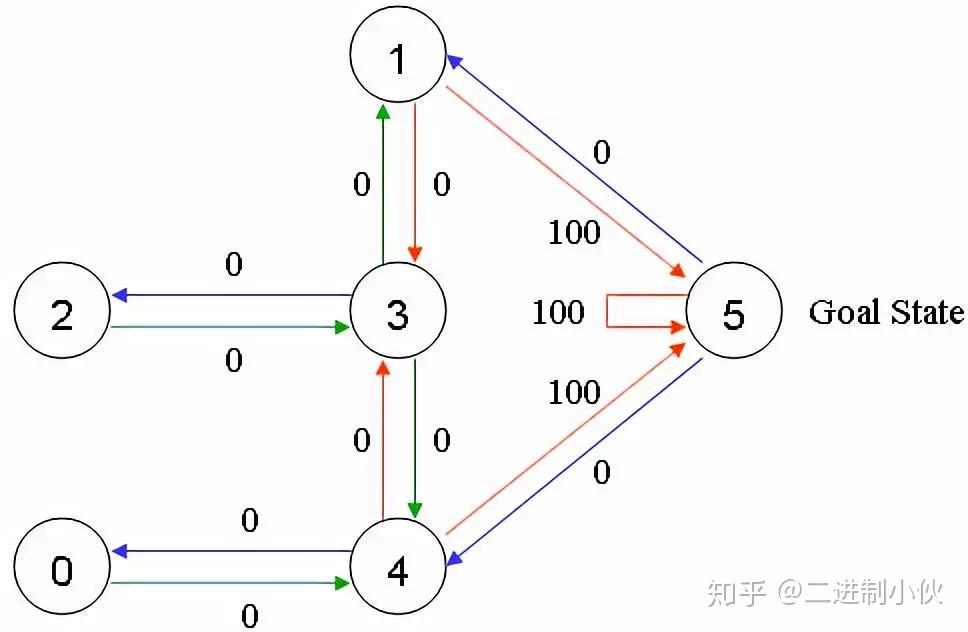
假设 Agent 当前的位置是在 2 号房间,这里就将 Agent 所在的位置做为“状态”,也就是 Agent 当前的状态是 2,当前 Agent 只能移动到 3 号房间,当它移动到 3 号房间的时候,状态就变为了 3,此时得到的奖励是 0 分。而 Agent根据箭头的移动则是一个“行为”。根据状态与行为得到的奖励可以组成以下矩阵。R代表当前奖励:
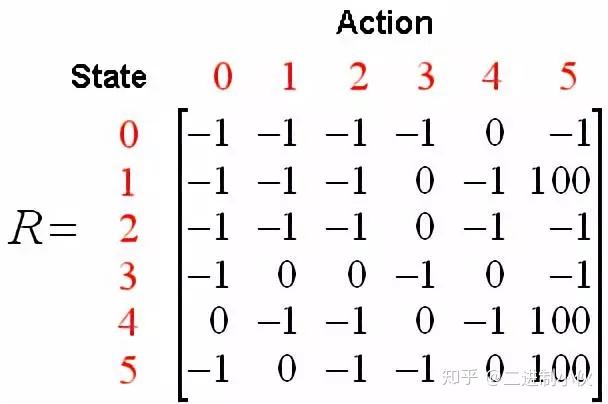
同时,可以使用一个 Q 矩阵,来表示 Agent 学习到的知识,在图 1.4 中,“-1”表示不可移动的位置,比如从 2 号房间移动到 1 号房间,由于根本就没有门,所以没办法过去。

该 Q 矩阵就表示Agent 在各种状态下,做了某种行为后自己给打的分,也就是将经验数据化,由于 Agent 还没有行动过,所以这里全是 0。在 Q-Learning算法中,计算经验得分的公式如下:
Q(state, action)=Q(state, action) + α(R(state, action) + Gamma* Max[Q(next state, all actions)]- Q(state, action))
当α的值是 1 时,公式如下:
Q(state, action)=R(state, action) + Gamma * Max[Q(next state, allactions)]
state: 表示 Agent 当前状态。
action: 表示 Agent 在当前状态下要做的行为。
next state: 表示 Agent在 state 状态下执行了 action行为后达到的新的状态。
Q(state, action): 表示 Agent 在 state 状态下执行了 action 行为后学习到的经验,也就是经验分数。
R(state, action): 表示 Agent 在 state 状态下做 action 动作后得到的即时奖励分数。
Max[Q(next state, all actions)]: 表示 Agent 在 next state 状态下,遍历所有action之后所能获得的最大经验分数
Gamma: γ,表示折损率,也就是未来的经验对当前状态执行 action 的重要程度。
(2) 算法
Agent 通过经验去学习。Agent将会从一个状态到另一个状态这样去探索,直到它到达目标状态。我们称每一次这样的探索为一个场景(episode)。
每个场景就是 Agent 从起始状态到达目标状态的过程。每次Agent 到达了目标状态,程序就会进入到下一个场景中。
1. 初始化 Q 矩阵,并将初始值设置成 0。
2. 设置好参数 γ 和得分矩阵 R。
3. 循环遍历场景(episode):
(1)随机初始化一个状态 s。
(2)如果未达到目标状态,则循环执行以下几步:
① 在当前状态 s 下,随机选择一个行为 a。
② 执行行为 a 得到下一个状态 s`。
③ 使用 Q(state, action)=R(state, action) + Gamma * Max[Q(nextstate, all actions)]公式计算 Q(state, action) 。
④ 将当前状态 s 更新为 s`。
设当前状态 s 是 1, γ=0.8和得分矩阵 R,并初始化 Q 矩阵:

由于在 1 号房间可以走到 3 号房间和 5 号房间,现在随机选一个,选到了 5 号房间。现在根据公式来计算,Agent 从 1 号房间走到 5 号房间时得到的经验分数 Q(1, 5) :
1.当 Agent 从 1 号房间移动到 5 号房间时,得到了奖励分数 100(即:R(1, 5)=100)。
2.当 Agent 移动到 5 号房间后,它可以执行的动作有 3 个:移动到 1 号房间(0 分)、移动到 4 号房间(0分)和移动到 5 号房间(0分)。注意,这里计算的是经验分数,也就是 Q 矩阵,不是 R 矩阵!
所以,Q(1, 5)=100 + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)]=100 +0.8 * Max{0, 0, 0}=100
(已经达到目标状态5,所以进入下一个场景episode)
在次迭代进入下一个episode:
随机选择一个初始状态,这里设 s=3,由于 3 号房间可以走到 1号房间、 2 号房间和 4 号房间,现在随机选一个,选到了 1 号房间。
步骤同上得:Q(3, 1)=0 + 0.8 * Max[Q(1, 3), Q(1, 5)]=0 + 0.8* Max{0, 100}=0 + 0.8 * 100=80
即:

马尔科夫决策过程: 由于在agent对系统进行actions后,得到的结果不一定就是预测好的,即得到的结果一部分是随机的,一部分处于agent的控制下,因此agent与环境之间的交互通常被构建为马尔科夫决策过程。
CAPES: 在CAPES环境中,我们将目标系统视为环境,调优模块作为agent添加到环境中,agent观察目标系统的状态,然后对目标系统采取action,采取action之后会得到相应的奖励和新的state。
Q-Learning: Q(S,a)=r + γ max Q(S',a') ,r代表奖励reward。这个公式被称为贝尔曼公式,它能够解决信贷分配问题(也就是前面提到得action和reward之间的延迟问题),因为迭代求解这个方程不需要知道动作和奖励之间的延迟。但是只使用Q-Learning的贝尔曼公式有一个致命问题,那就是状态空间过大的话,Q-table会变得无限大,解决这个问题的办法是通过神经网络实现q-table。输入state,输出不同action的q-value。神经网络通常使用非线性动作值函数逼近器来表达Q-function,然而,当使用非线性函数逼近器时,强化学习是不稳定的,甚至是发散的,所以这种就要使用经验重放来解决这个问题。
经验重放: 强化学习由于state之间的相关性存在稳定性的问题,因为智能体去探索环境时采集到的样本是一个时间序列,样本之间具有连续性,所以需要打破时间相关性,解决的办法是在训练的时候存储当前训练的状态到记忆体M,更新参数的时候随机从M中抽样mini-batch进行更新。具体地,M中存储的数据类型为 <s,a,r,s′>,M有最大长度的限制,以保证更新采用的数据都是最近的数据。经验重放的最终目的是防止过拟合。
· Exploration:在更新Q-function时,只针对已经被agent处理的state进行Q-function的更新,对于未处理的state,只能用以前的经验进行处理,所以需要agent进行尽可能多的探索(在训练过程中),所以在刚开始训练的时候,为了能够看到更多可能的情况,需要对action加入一定的随机性。
· Exploitation:随着训练的加深,逐渐降低随机性,也就是降低随机action出现的概率。
4 算法
整个存储系统调优模型如图所示:(1) Monitor agent 用来收集performance indictors(即state)和reward,并发送到后台接口程序。(2)后台接口程序将performanceindictors 和reward放入Replay DB,Replay DB中存储的数据类型为 <s,a,r,s′>,Replay DB的设计就是为了上述所讲的经验重放。(2)深度增强学习引擎调用Replay DB中的数据进行训练,在固定的时间间隔中,深度增强学习引擎将action发送到后台接口程序,然后后台接口程序将action发送到Control agent ,Control agent 根据action对目标系统做出相应的改变。
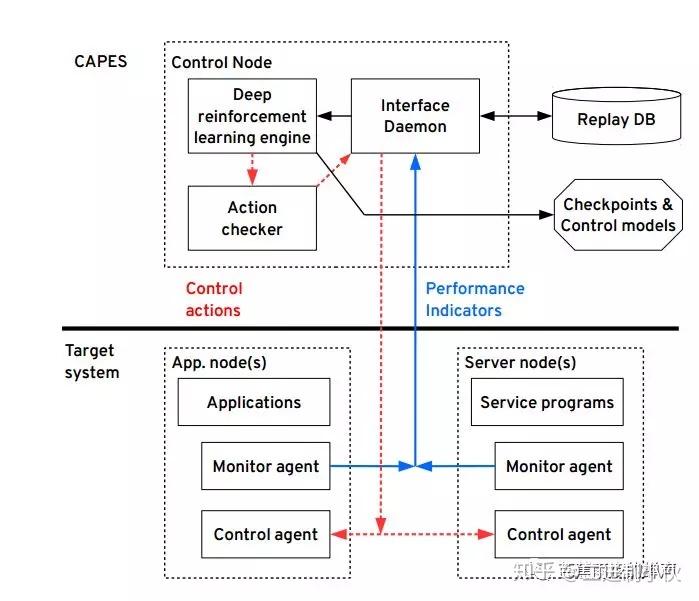
算法过程总结如下:
1.随机初始化一个状态 s,初始化记忆池(Replay DB),设置观察值。
2.循环遍历(是永久遍历还是只遍历一定次数这个自己设置):
(1) 根据策略选择一个行为(action)。
(2) 执行该行动(aaction),得到奖励(reward)、执行该行为后的状态 s`和游戏是否结束 done。
(3) 保存 s, a, r, s`, done 到记忆池里。
(4) 判断记忆池里的数据是否足够(即:记忆池里的数据数量是否超过设置的观察值),如果不够,则转到(5)步。
①在记忆池里随机抽取出一部分数据做为训练样本。
②将所有训练样本的 s`做为神经网络的输入值,进行批量处理,得到 s`状态下每个行为的 q 值的表。
③根据公式计算出 q 值表对应的 target_q 值表。
公式:Q(s, a)=r +Gamma * Max[Q(s`, all actions)]
④使用 q 与 target_q 训练神经网络。
(5) 判断游戏(目标系统是否运行结束)是否结束。
①游戏结束,给 s 随机设置一个状态,再执行(1), (2),(3),(4)。
②未结束,则当前状态 s 更新为 s`(意思就是当前的状态变成 s`,以当前的 s`去action,得到r,得到执行该行为后的状态 s`'和游戏是否结束 done)。

5 具体实现过程
目标系统:Lustre 文件系统,Red Hat Enterprise Linux/CentOS 7, Python 3.5
代码编写实现:Python3
深度神经网络实现:Tensorflow
Replay DB:SQLite
工作负载采用filebench实现
6 实验过程与结果分析
(1) 随机读写比率如下:9 : 1, 4: 1, 1 : 1, 1 : 4, 1 : 9
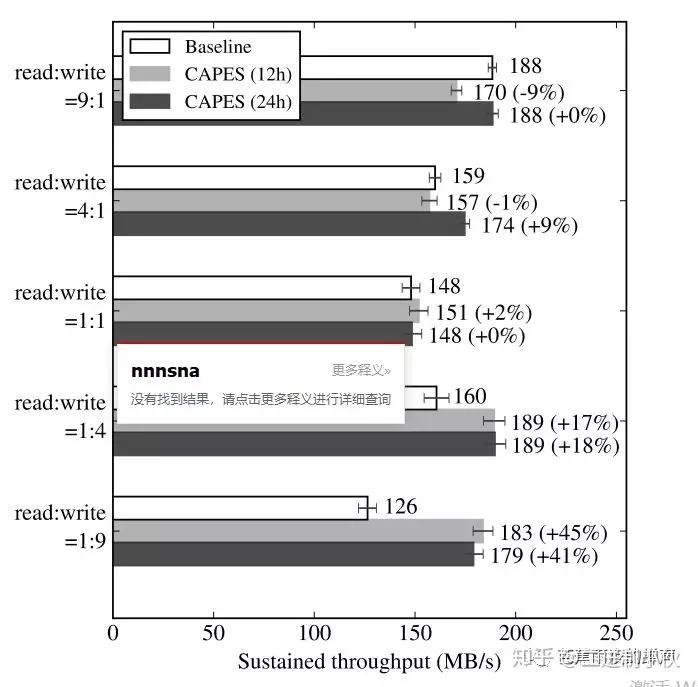
我们可以看到,当写占据主导时,调优系统的作用比较明显,同时可以看到,训练24小时的效果明显好于训练12小时。因此,训练需要较长时间来进行聚集,拟合。
(2) filebench文件服务器调优:filebench文件服务器是一种合成负载,用来模拟忙碌的I/O文件负载,这种文件负载大型数据存储中心很常见,具体filebench模拟过程参考filebench操作。连续写调优:对采用连续写的工作负载进行调节。
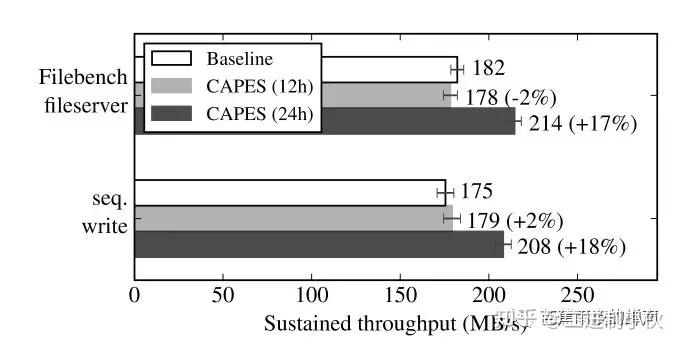
从实验结果我们可以看到,对于Filebenchfileserver,采用12小时训练的CAPES,调优效果不明显,甚至有变差的趋势,这是因为使用Q-Learning时,系统的状态空间过大,Q-Learning的训练还有没拟合,因此需要更长的时间进行聚合,可以看到24小时的聚合效果更好,I/O生产量增长了17%。
7 总结与展望
在这个实验中,CAPES能够找到分布式存储系统的最佳拥塞窗口大小,最佳I/O速率限制等值。相比较人工调整存储系统参数,CAPES是基于无监督学习的,能够随时随地自动调整,而且由于是非入侵式的,在调整时不影响系统的正常工作,结合深度学习,CAPES能够在几乎无限的参数空间中找到最佳值。因此CAPES能够减少管理成本和提升计算机效率。虽然实验用在了分布式存储系统上,但实验没有做任何前提假设,而且CAPES不需要对系统有前提认知,因此CAPES可以用在任何存储系统的优化上。
文献:CAPES: Unsupervised Storage Performance Tuning Using Neural Network-Based Deep Reinforcement Learning
公司名称: 亚游-亚游娱乐-注册登录站
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

